NatureNet DataHub
Geospatial ML platform for invasive species monitoring — from drone orthomosaic to validated training set, with full provenance every step.
- Year
- 2025
- Role
- Independent — product, design, engineering
- Status
- Live (auth required)
- Stack
- AWS (S3, Lambda, API Gateway, DynamoDB, CloudFront) · React + MapLibre · RF-DETR · GDAL
The problem
Field biologists and land managers collect enormous drone datasets to track invasive plant populations, but the raw imagery is useless without a pipeline: tiles have to be generated, detections run, outputs reviewed, and errors corrected. Most teams stitch this together manually across disconnected tools — so the data piles up faster than anyone can use it, and once it does, nobody can answer the only question that matters at audit time: where did this number come from?
What it does
- Ingests drone orthomosaics against a canonical site identity. Reflying the same location produces a new orthomosaic version, not a sibling — so detections accumulate as a time series on one site rather than fragmenting across duplicates. Site identity, not filename, is the spine of the data model.
- Tiles via a GDAL-backed batch pipeline, with raw orthomosaics moving from hot S3 to S3-IA and ultimately Glacier Deep Archive on an age-based lifecycle policy. Tiles stay hot for fast viewer reads; the originals stay queryable as scientific records without burning hot-storage cost. Hot data stays cheap to read; cold data stays cheap to keep.
- Runs RF-DETR species detection as a serverless batch workload against a tracked model registry. Every detection lands in DynamoDB with full provenance — source orthomosaic version, model version, inference run, tile coordinates, geographic bounds. Any number on the screen can be traced all the way back to the pixel and the model that produced it.
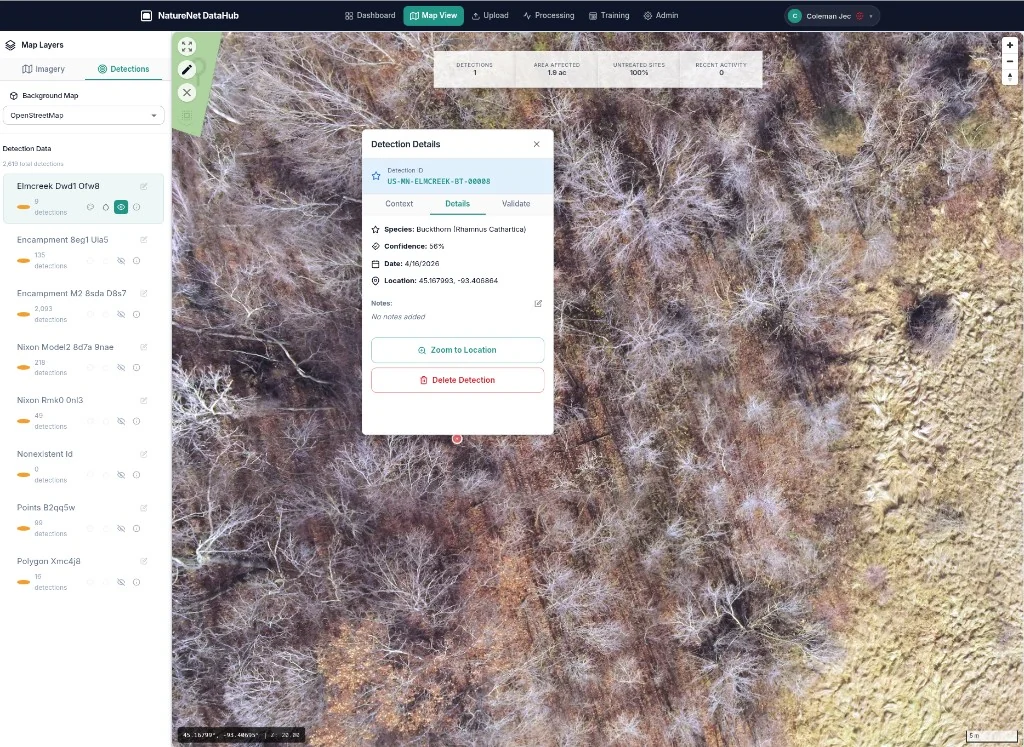
- Presents an interactive MapLibre viewer for reviewers to validate, correct, and annotate detections in-context. Species taxonomy, site categories, and attribute fields are managed as data, not hardcoded — adding a new species or a new attribute doesn't require a code change or a deploy.
- Exports in multiple formats — COCO for the next training cycle, GeoJSON for QGIS / ArcGIS, CSV and parquet for analysts, and the original GeoTIFFs for backup or third-party processing. One canonical detection record drives every export, so the COCO set, the GeoJSON layer, and the analyst's CSV are all the same source of truth in different shapes.
What I'm proud of
The loop is closed end-to-end: every correction a reviewer makes feeds back into improving the model. The same system that produces detections also produces the ground truth that makes them better over time.
The other thing I'm proud of is the data management discipline underneath that loop. A detection on the screen isn't a number — it's a node in a graph that tracks back to its source orthomosaic version, the model version that produced it, the inference run it came from, and the canonical site it belongs to. Reflying a site doesn't fragment the data; it deepens it. Adding a species or an attribute doesn't require a deploy. Old orthos don't get deleted to save money — they tier into Glacier and stay queryable. This is the same provenance discipline I bring to media work, applied to geospatial data: nothing becomes an orphan, and any export handed to a researcher comes with the chain of custody attached.
Tech notes
Fully serverless backend on AWS (Lambda + API Gateway + DynamoDB) for cost efficiency during idle periods. Frontend is a React SPA hosted on S3 + CloudFront with MapLibre GL for rendering. Tiling runs as asynchronous batch jobs triggered by S3 uploads. The data model is normalized around three first-class entities — Site (canonical, persistent), Survey (a single flight on a site, versioned), and Detection (output of one model run on one survey) — with model versions and species taxonomy as first-class records alongside. That separation is what makes "re-run model M against survey S from 2024" a real query rather than a thought experiment.
What's next: a reviewer audit log so every validation and correction is attributable and reversible, and reproducible training runs that pin each model version to a frozen training-set snapshot — closing the provenance chain from raw image all the way through to model weights.